Spark 多个Stage执行是串行执行的么?
本文共 1089 字,大约阅读时间需要 3 分钟。
上次在做内部培训的时候,我讲了这么一句:
一个Job里的Stage都是串行的,前一个Stage完成后下一个Stage才会进行。
显然上面的话是不严谨的。
看如下的代码:
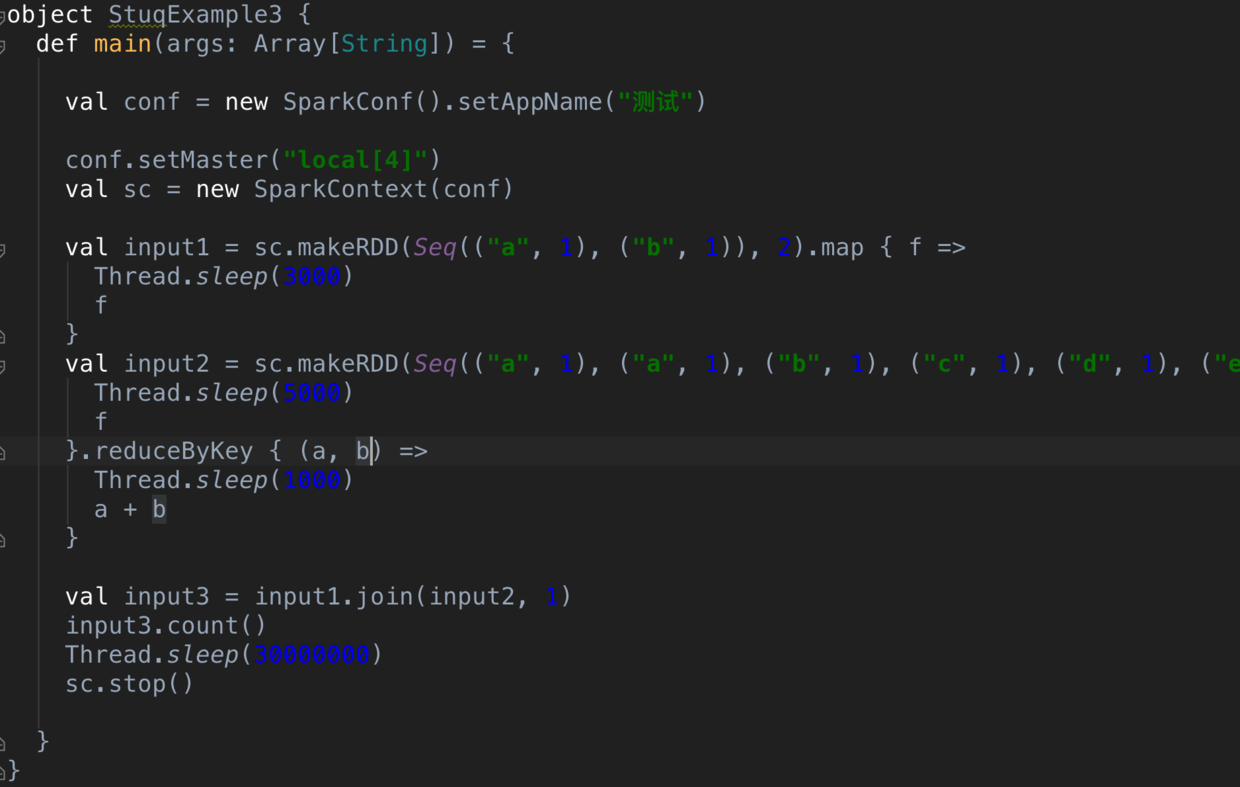
Snip20160903_17.png
这里的话,我们构建了两个输入(input1,input2),input2带有一个reduceByKey,所以会产生一次Shuffle,接着进行Join,会产生第二次Shuffle(值得注意的是,join 不一定产生新的Stage,我通过强制变更join后的分区数让其发生Shuffle ,然后进行Stage的切分)。
所以这里一共有两次Shuffle,产生了四个Stage。 下图是Spark UI上呈现的。那这四个Stage的执行顺序是什么呢?
Snip20160903_11.png
再次看Spark UI上的截图:
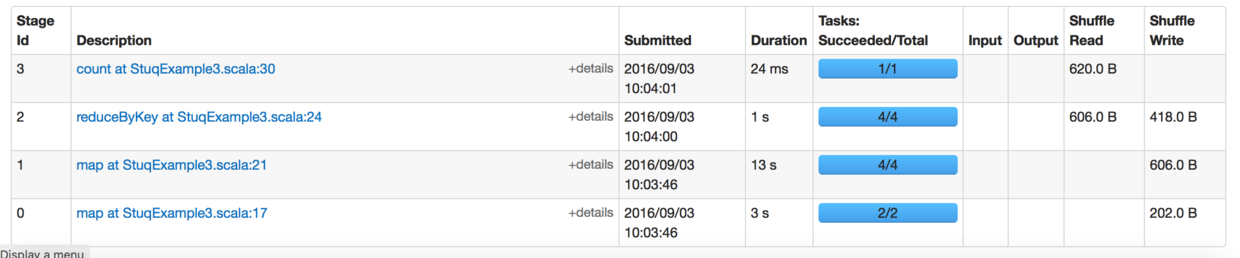
Snip20160903_16.png
我们仔细分析下我们看到现象:
首先我们看到 Stage0,Stage 1 是同时提交的。
Stage0 只有两条记录,并且设置了两个Partition,所以一次性就能执行完,也就是3s就完成了。
Stage1 有四个分区,六条记录,记录数最多的分区是两条,也就是需要执行10秒,如果完全能并行执行,也就是最多10s。但是这里消耗了13秒,为什么呢?点击这个13秒进去看看:

Snip20160903_15.png
我们看到有两个task 延迟了3秒后才并行执行的。 根据上面的代码,我们只有四颗核供Spark使用,Stage0 里的两个任务因为正在运行,所以Stage1 只能运行两个任务,等Stage0 运行完成后,Stage1剩下的两个任务才接着运行。
之后Stage2 是在Stage1 执行完成之后才开始执行,而Stage3是在Stage2 执行完成才开始执行。
现在我们可以得出结论了:
Stage 可以并行执行的
存在依赖的Stage 必须在依赖的Stage执行完成后才能执行下一个Stage
Stage的并行度取决于资源数
我么也可以从源码的角度解释这个现象:
Snip20160903_18.png
我们看到如果一个Stage有多个依赖,会深度便利,直到到了根节点,如果有多个根节点,都会通过submitMissingTasks 提交上去运行。当然Spark只是尝试提交你的Tasks,能不能完全并行运行取决于你的资源数了。
这里再贡献一张画了很久的示意图,体现了partition,shuffle,stage,RDD,transformation,action,source 等多个概念。
转载地址:http://jkcgo.baihongyu.com/
你可能感兴趣的文章
如何防止http请求数据被篡改
查看>>
MyEclipse 2013集成JRebel
查看>>
indexOf()
查看>>
go语言学习
查看>>
tidb 安装
查看>>
phpcms V9.6.0版本整合百度ueditor1.4.3.2,包括水图片上传水印
查看>>
Tiptop GP中Excel的控制方法
查看>>
JavaWeb分页技术总结
查看>>
基于unity框架构造IOC容器
查看>>
Windows更新导致的打印问题
查看>>
Chrome 控制台不完全指南
查看>>
Notification与多线程
查看>>
高可用、高扩展性、负载均衡
查看>>
VIM用法
查看>>
oscache.properties文件配置
查看>>
新建索引的一些原则
查看>>
redis发布了集群版3.0.0 beta
查看>>
使用Gradle在嵌入式Web容器Jetty中运行Web应用
查看>>
100-98
查看>>
Innodb中的事务隔离级别和锁的关系
查看>>